Where do those massive ARP tables come from?

Hi list, I have a bunch of three routers running in a project, let's call them A, B and C. They connect to multiple AS upstream and internally via OSPF and RIPng. While B is based on an (ancient) Ubuntu 12.04.5 and (also ancient) Quagga (0.99.20.1), A and C run very recent CentOS 7 and FRR 6.0.2. B performs perfectly, while A and C put massive pressure on some Cisco switches they're connected to (OSPF and RIPng): They're sending about 2k ARP requests per second each. Looking at the ARP table (``ip nei show'') of A and C, I see about 20k entries, almost all of them in nud "FAIL" (unreachable). Most of them are IPs within the customer's AS (this is VLAN310 in the graphs attached), but some are random public IPv4 addresses. I did compare all sysctl settings to no avail, they're all set in a sane and safe manner. Every daemon not needed or adding not necessary complexity (like NetworkManager) is disabled and not running on A and C. ARP flux can be ruled out, too. Any idea what is going on here? Best Bernd
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Any chance you have a default route pointing to a local interface, or have an invalid onlink route making it think destinations are local when they're not? What does you config and routing table look like? Are all the extraneous arps pointing out the same interface? On Thu, Jul 11, 2019 at 3:54 AM Bernd <bernd@kroenchenstadt.de> wrote:
Hi list,
I have a bunch of three routers running in a project, let's call them A, B and C. They connect to multiple AS upstream and internally via OSPF and RIPng.
While B is based on an (ancient) Ubuntu 12.04.5 and (also ancient) Quagga (0.99.20.1), A and C run very recent CentOS 7 and FRR 6.0.2.
B performs perfectly, while A and C put massive pressure on some Cisco switches they're connected to (OSPF and RIPng): They're sending about 2k ARP requests per second each.
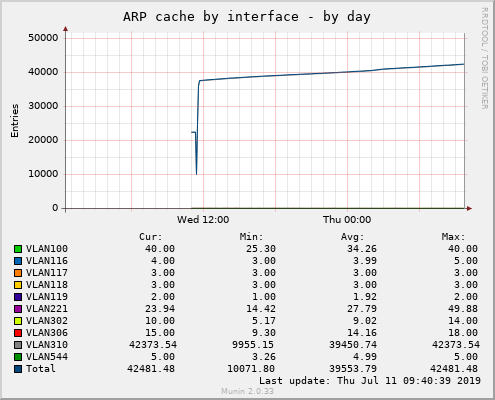
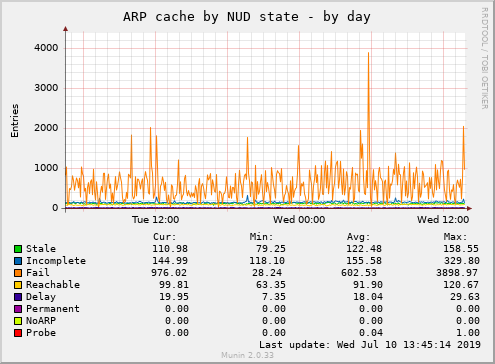
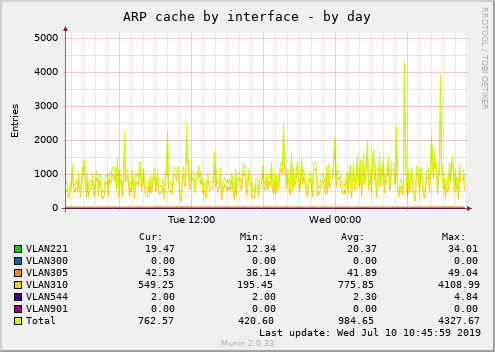
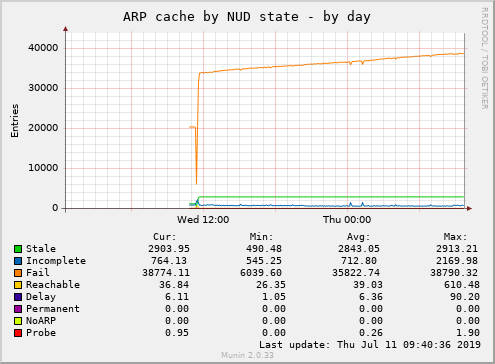
Looking at the ARP table (``ip nei show'') of A and C, I see about 20k entries, almost all of them in nud "FAIL" (unreachable). Most of them are IPs within the customer's AS (this is VLAN310 in the graphs attached), but some are random public IPv4 addresses.
I did compare all sysctl settings to no avail, they're all set in a sane and safe manner. Every daemon not needed or adding not necessary complexity (like NetworkManager) is disabled and not running on A and C. ARP flux can be ruled out, too.
Any idea what is going on here?
Best
Bernd_______________________________________________ frog mailing list frog@lists.frrouting.org https://lists.frrouting.org/listinfo/frog
-- Don Slice Cumulus Networks
Am 2019-07-11 13:39, schrieb Don Slice:
Any chance you have a default route pointing to a local interface, or have an invalid onlink route making it think destinations are local when they're not? What does you config and routing table look like? Are all the extraneous arps pointing out the same interface?
Thanks a lot, Don! Your first thought was the perfect match. The machines indeed had (for whatever historical reasons) a static route pointed onto themselves. After removing it, the switch CPU load dropped massively (from about 85% to less then 40%). I assume the blackhole never was hit by traffic that was meant to be sent there? Now: funny_hostname# sh ip route a.b.c.d Routing entry for 0.0.0.0/0 Known via "ospf", distance 110, metric 190, best Last update 00:26:58 ago * n.o.p.q, via bond1.310 Routing entry for 0.0.0.0/0 Known via "static", distance 240, metric 0 Last update 1d00h53m ago unreachable (blackhole) Best Bernd
On Thu, Jul 11, 2019 at 3:54 AM Bernd <bernd@kroenchenstadt.de> wrote:
Hi list,
I have a bunch of three routers running in a project, let's call them A, B and C. They connect to multiple AS upstream and internally via OSPF and RIPng.
While B is based on an (ancient) Ubuntu 12.04.5 and (also ancient) Quagga (0.99.20.1), A and C run very recent CentOS 7 and FRR 6.0.2.
B performs perfectly, while A and C put massive pressure on some Cisco switches they're connected to (OSPF and RIPng): They're sending about 2k ARP requests per second each.
Looking at the ARP table (``ip nei show'') of A and C, I see about 20k entries, almost all of them in nud "FAIL" (unreachable). Most of them are IPs within the customer's AS (this is VLAN310 in the graphs attached), but some are random public IPv4 addresses.
I did compare all sysctl settings to no avail, they're all set in a sane and safe manner. Every daemon not needed or adding not necessary complexity (like NetworkManager) is disabled and not running on A and C. ARP flux can be ruled out, too.
Any idea what is going on here?
Best
Bernd_______________________________________________ frog mailing list frog@lists.frrouting.org https://lists.frrouting.org/listinfo/frog
--
Don Slice Cumulus Networks
Am 2019-07-11 14:15, schrieb Bernd:
Am 2019-07-11 13:39, schrieb Don Slice:
Any chance you have a default route pointing to a local interface, or have an invalid onlink route making it think destinations are local when they're not? What does you config and routing table look like? Are all the extraneous arps pointing out the same interface?
Thanks a lot, Don! Your first thought was the perfect match.
The machines indeed had (for whatever historical reasons) a static route pointed onto themselves. After removing it, the switch CPU load dropped massively (from about 85% to less then 40%).
I assume the blackhole never was hit by traffic that was meant to be sent there?
Now:
funny_hostname# sh ip route a.b.c.d Routing entry for 0.0.0.0/0 Known via "ospf", distance 110, metric 190, best Last update 00:26:58 ago * n.o.p.q, via bond1.310
Routing entry for 0.0.0.0/0 Known via "static", distance 240, metric 0 Last update 1d00h53m ago unreachable (blackhole)
Hi again, I did miss that deletion of that static route made A and C disappear from the adjacent neighbors as next hop. So, I added it again (made sure staticd, which was introduced with FRR 6.0, is running): ip route 0.0.0.0/0 a.b.c.d ip route 0.0.0.0/0 Null0 240 which leads to A and C showing up again on the adjacent (via OSPF) Switches – but instantly the problem reappears... BB001#show ip route 0.0.0.0 Routing entry for 0.0.0.0/0, supernet Known via "ospf 1234", distance 110, metric 91, candidate default path, type extern 1 Last update from a.b.c.5 on Vlan310, 00:02:04 ago Routing Descriptor Blocks: a.b.c.5, from e.f.g.227, 00:02:04 ago, via Vlan310 Route metric is 91, traffic share count is 1 * a.b.c.4, from a.b.c.4, 00:02:04 ago, via Vlan310 Route metric is 91, traffic share count is 1 a.b.c.3, from e.f.g.225, 00:02:04 ago, via Vlan310 Route metric is 91, traffic share count is 1 In the end I got three machines peering with multiple BGP neighbours (full feed), and I want to have all of them announcing themselves as possible gateway. This should be trivial, no? Thanks for any hint! Bernd
participants (2)
-
 Bernd
Bernd -
 Don Slice
Don Slice